- Cross-modal distillation — distills vision-enabled teacher policies into vision-free students, producing policies invariant to visual conditions.
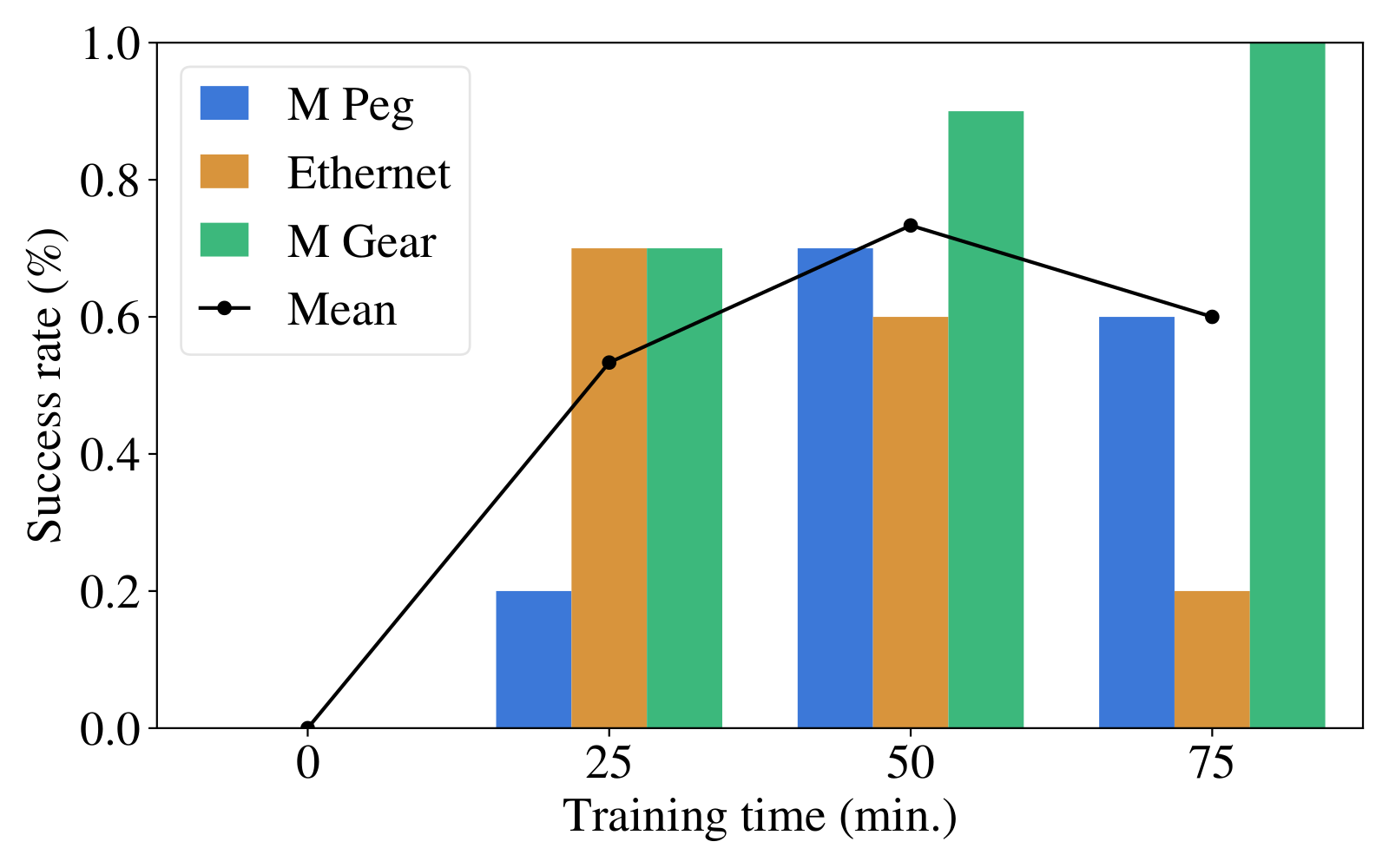
- Efficient generalization — co-training on 3 tasks enables zero-shot transfer to 8 unseen connectors, with full success achievable via brief fine-tuning with distillation.
- Real-world validation — 95% overall success on the NIST Assembly Benchmark after ~50 min of robot interaction, outperforming all baselines in robustness and adaptability.
VE2VF Training Pipeline
I A vision-enabled teacher is trained via human-in-the-loop RL using camera images alongside proprioceptive inputs. II The teacher is distilled into a vision-free student that uses only pose, twist, and wrench — no cameras at deployment. III (Optional) A new task-specific teacher is trained and used to fine-tune the student in just 10 additional minutes.
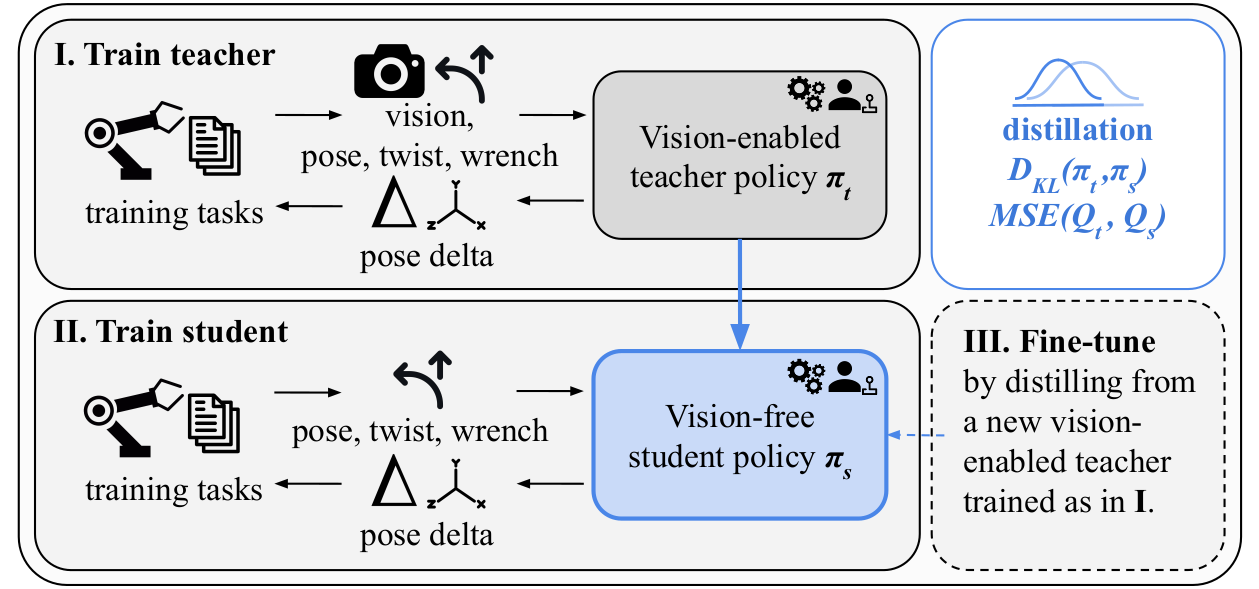
Fig. 2: VE2VF training stages.