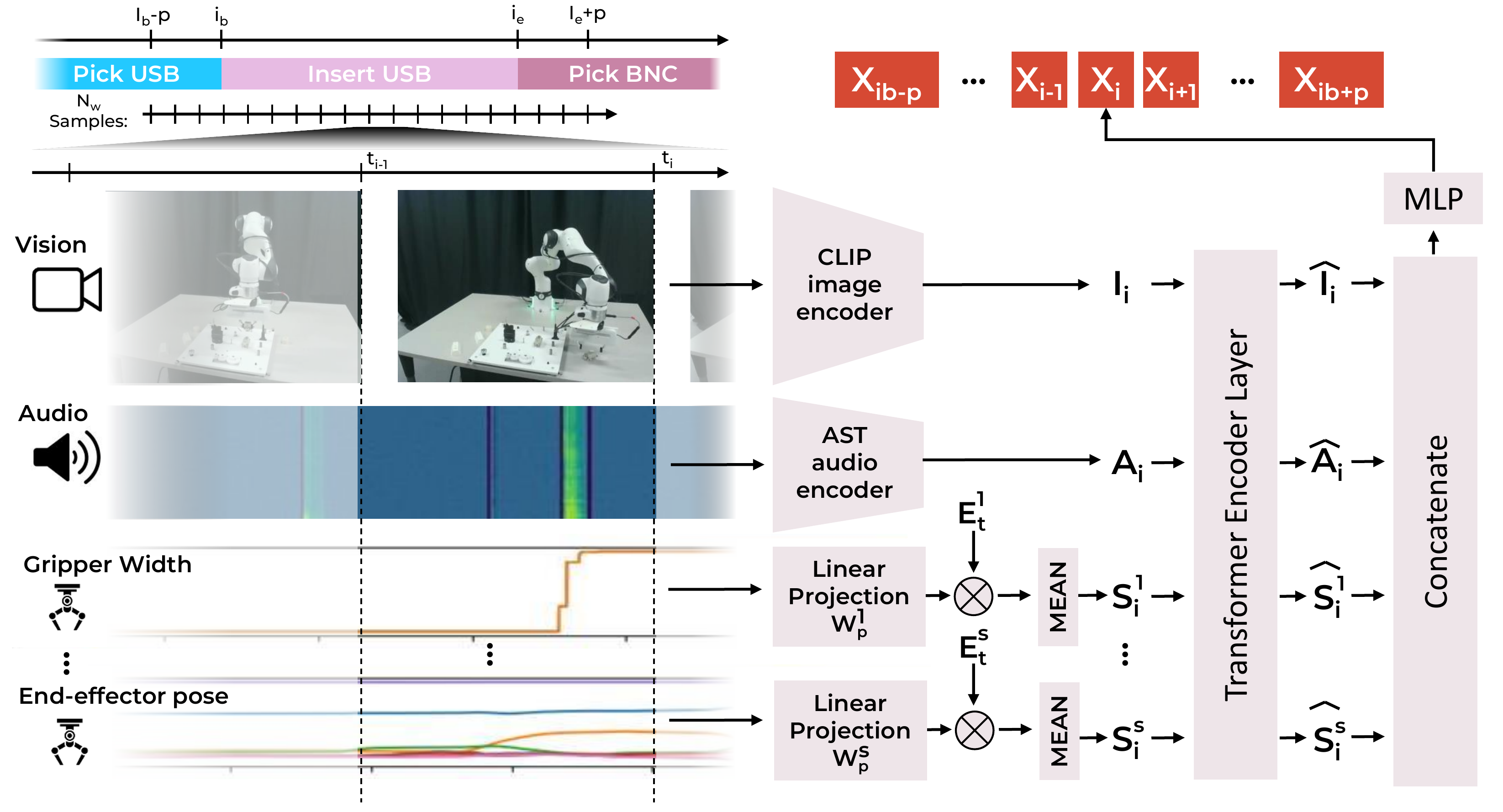
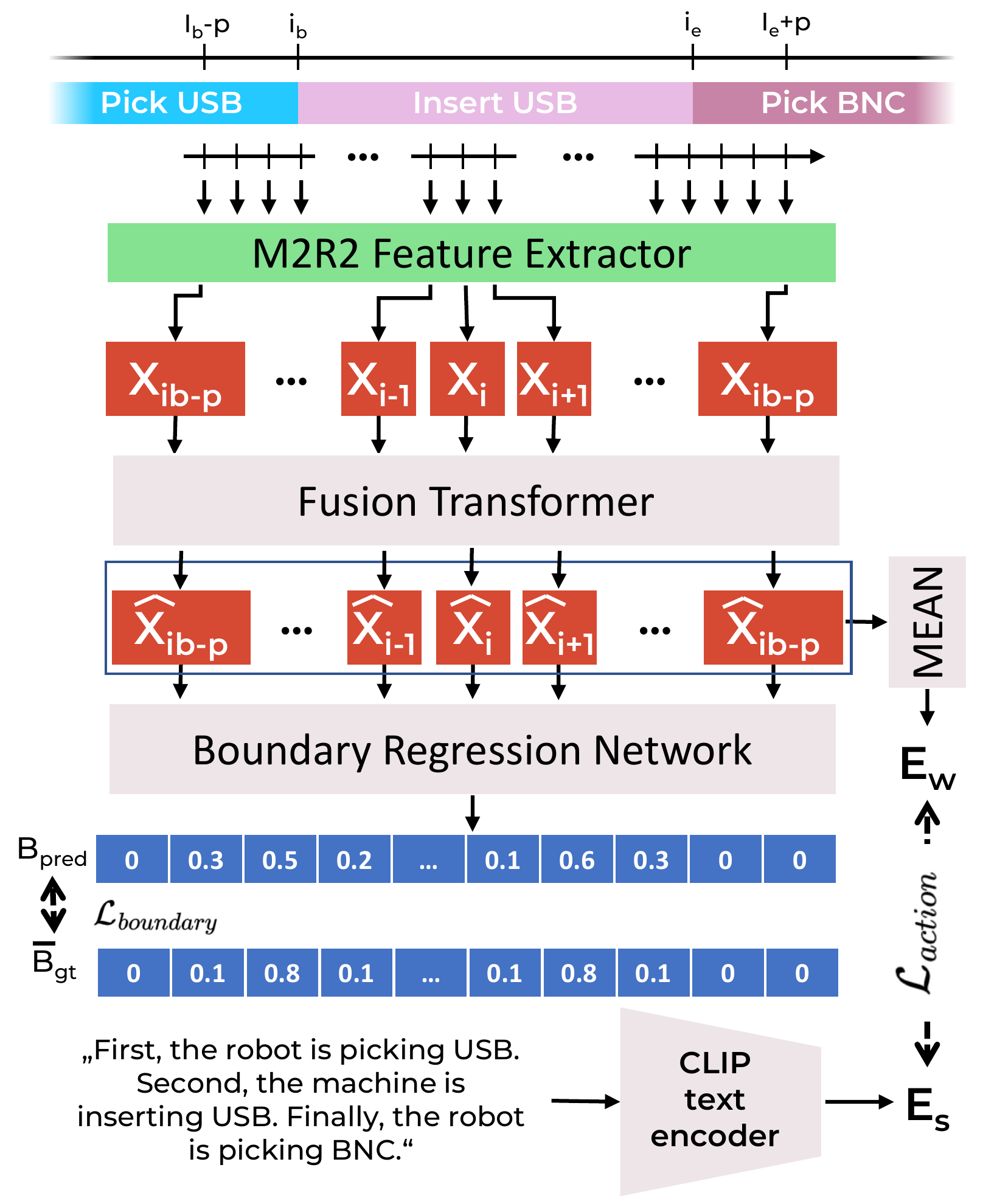
- Multimodal feature extractor — a deep-learning-based M2R2 feature extractor that fuses vision, audio, and proprioceptive data for robotic temporal action segmentation.
- Novel training strategy — a modular training approach that decouples feature extraction from the TAS model, enabling reuse of learned features with any state-of-the-art TAS architecture (MSTCN, ASRF, DiffAct, …).
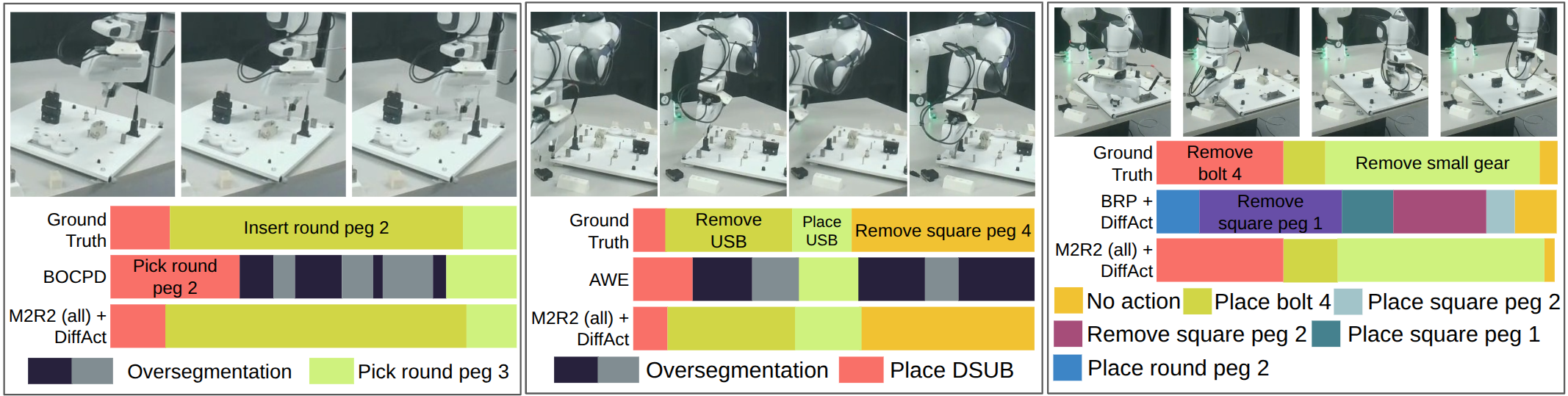
- Extensive evaluation — state-of-the-art performance on three robotic datasets (REASSEMBLE, (Im)PerfectPour, JIGSAWS) and an ablation study quantifying the contribution of each sensor modality.
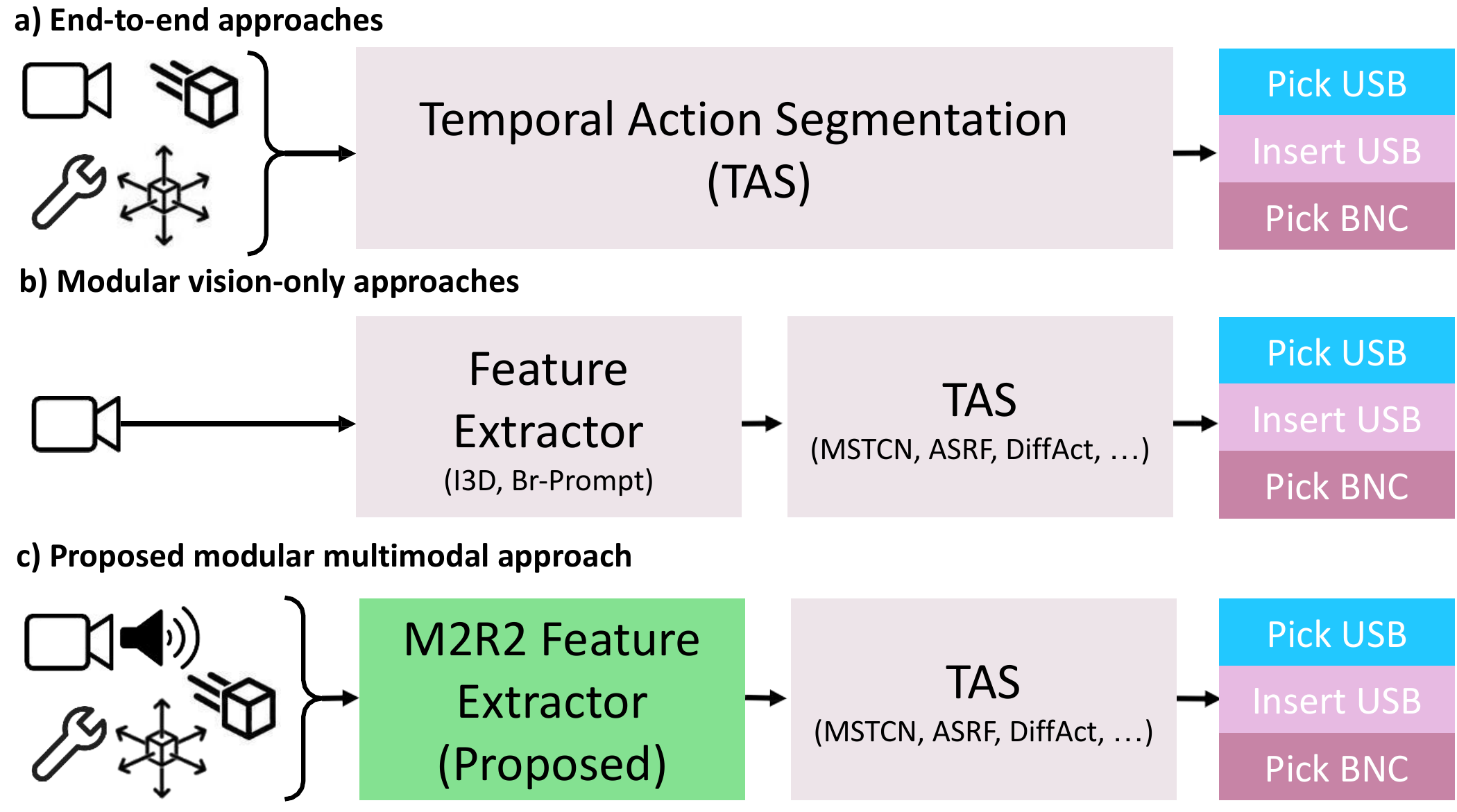
Fig. 1: Many multimodal approaches follow an end-to-end paradigm (a). Modular approaches train the feature extractor and TAS model separately but rely on vision-only extractors (b). We propose the M2R2 feature extractor, which leverages multimodal information and integrates with diverse TAS models (c).