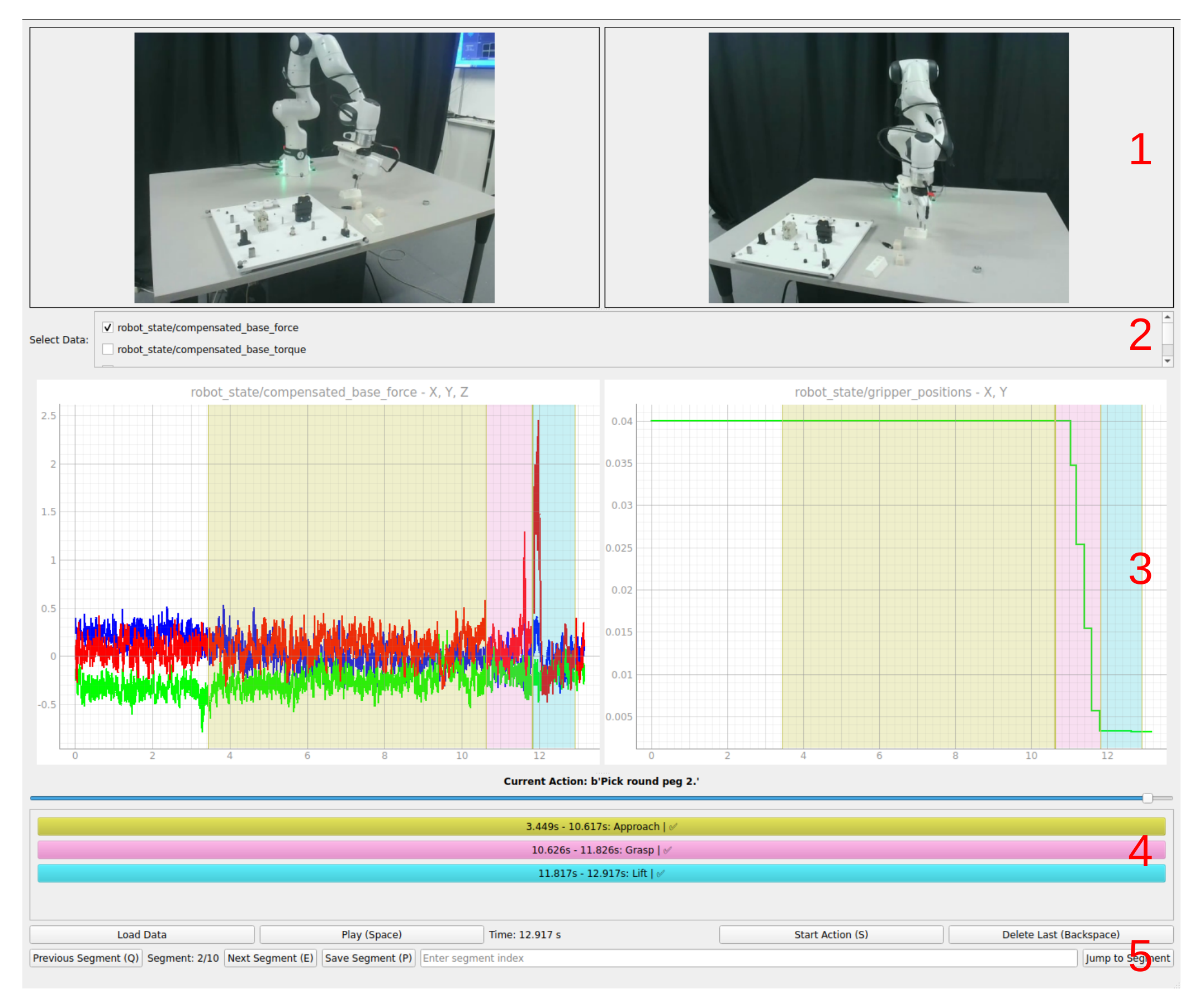
- Synchronized multi-modal visualization — time-synchronized display of multi-view RGB video streams and robot-specific time-series signals (end-effector pose, gripper state, force/torque) for precise boundary identification.
- Flexible dataset support — native handling of raw videos, frame-based datasets, ROS bag files (ROS1 & ROS2), the RLDS format (covering 71 datasets and 2.4M+ episodes in the Open X-Embodiment repository), and the REASSEMBLE dataset — no conversion required.
- Extensible dataset abstraction — a template-method design pattern decouples the visualization and annotation frontend from the underlying data format, allowing new datasets to be integrated with minimal effort.
- Keyboard-centric annotation interface — customizable shortcuts reduce mouse interaction overhead, achieving the lowest average per-action annotation time among compared tools (11.0 ± 1.2 s for vision-only, 18.5 ± 0.9 s with time-series data).
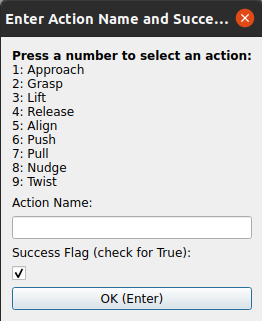
- Action segmentation and outcome annotation — support for marking action boundaries, assigning semantic action labels, and recording task outcomes (success or failure).
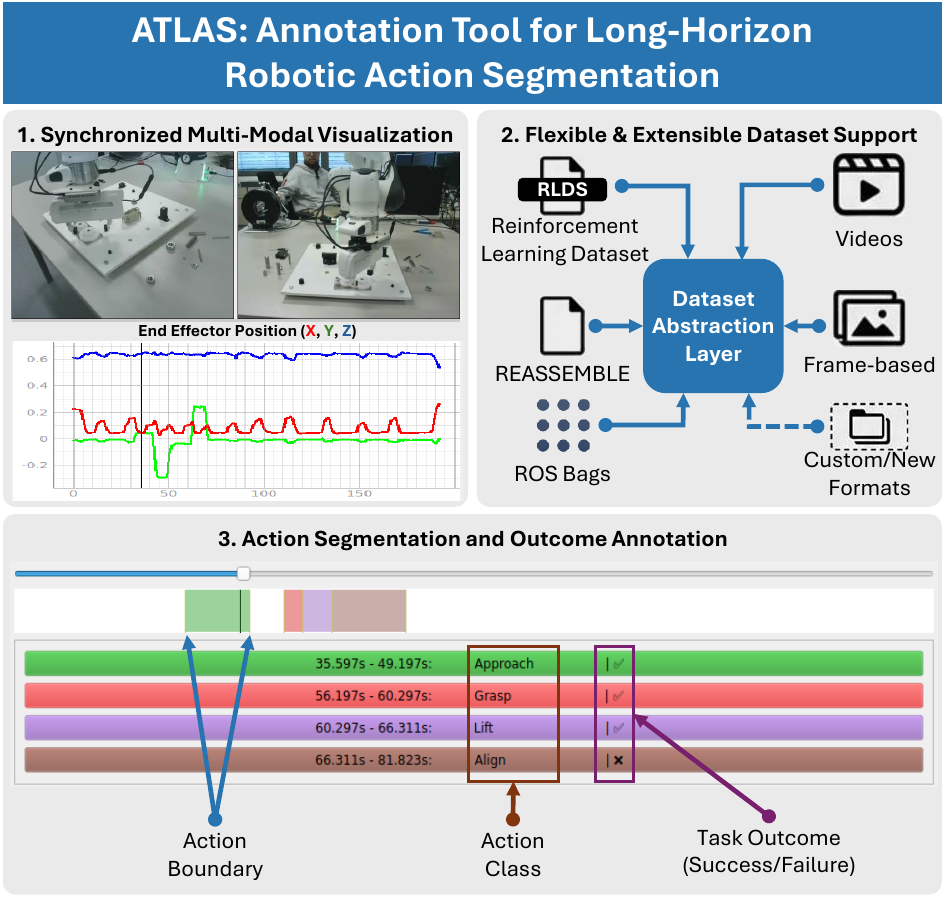
Fig. 1: ATLAS is a tool for long-horizon robotic action segmentation, supporting time-synchronized visualization of multi-modal data. It handles common robotics dataset formats and can be extended to new ones. The tool allows annotation of action boundaries, classes, and outcomes (success or failure).